So! Following my previous blog post where I scraped Amazon reviews of Yuval Harari’s Sapiens to create a wordcloud based on them, here I will compare results of sentiment analysis performed on Harari’s two books: Sapiens and Homo Deus.
A QUICK INTRO
For the context, Sapiens has been published originally in Hebrew in 2011. It, as Wikipedia puts it,
[Sapiens] surveys the history of humankind from the evolution of archaic human species in the Stone Age up to the twenty-first century.
It quickly became a bestseller, but it still took 4 years before Harari published his most recent book, and an overnight hit, Homo Deus:
Homo Deus, as opposed to the previous book, deals more with the abilities acquired by mankind (Homo sapiens) throughout the years of its existence while basing itself as the dominant being in the world, and tries to paint an image of the future of mankind, if any [Wikipedia]
So, in both books the historical, philosophical, economical and biological synthesis of the human species played a big role, and in this sense they are similar. Still, Sapiens was the first of its kind and it probably set high expectations for the follower book. Additionally, Homo Deus makes some bold predictions about the future of human kind in the world ruled by algorithms and AI, and any such speculation will have a very polarizing effect.
For this reason, my prediction is that Sapiens will receive more positive reviews than Homo Deus. And there’s only one way to find out if I’m right, so let’s get cracking!
SENTIMENT ANALYSIS
After loading necessary packages, I wrap up a scraping process described in my previous blog post into a function_page() function. I extract the first 12 pages of reviews for both books to have a comparable amount of data for analysis ( “Homo Deus” has been published in English only in September 2016). After some data cleaning, my data look like this:
# load packages
library(tidyverse)
library(XML)
library(xml2)
library(tidytext)
library(knitr)
### scaping the reviews
# product codes
sapiens_code = "1846558239"
homo_deus_code = "1910701874"
#Source funtion to Parse Amazon html pages for data
source("https://raw.githubusercontent.com/rjsaito/Just-R-Things/master/Text%20Mining/amazonscraper.R")
# extract first 12 pages of reviews for each book
pages <- 12
function_page <- function(page_num, prod_code){
url2 <- paste0("http://www.amazon.co.uk/product-reviews/",prod_code,"/?pageNumber=", page_num)
doc2 <- read_html(url2)
reviews <- amazon_scraper(doc2, reviewer = F, delay = 2)
reviews
}
sapiens_reviews <- map2(1:pages, sapiens_code, function_page) %>% bind_rows()
sapiens_reviews$comments <- gsub("\\.", "\\. ", sapiens_reviews$comments) #add space after each full stop
homo_deus_reviews <- map2(1:pages, homo_deus_code, function_page) %>% bind_rows()
homo_deus_reviews$comments <- gsub("\\.", "\\. ", homo_deus_reviews$comments) #add space after each full stop
head(homo_deus_reviews, 2) %>% kable()
| title | author | date | ver.purchase | format | stars | comments | helpful |
|---|---|---|---|---|---|---|---|
| Sapiens demanded a follow-up | Sussman | 6 February 2017 | 1 | Format: Hardcover | 4 | In his bold and provocative book Sapiens, Yuval Noah Harari gives us a lexicon on who we are, how we got here, and where we are going. Like all great blockbusters, Sapiens demanded a follow-up. Homo Deus, in which that likely apocalyptic future is imagined in every tangible fact, is that book. Harari is clearly a man who thinks for himself so there are a plethora of innovative ideas contained within the book. This provoking tome is a highly appealing developmental planner for the various ways in which we might to do more than is possible for ourselves. “Modernity is a deal,” Harari writes. “The entire contract can be abridged in a single phrase: hominids agree to give up meaning in exchange for power. ” That authority, Harari advocates may perhaps, in the near term, may give us superhuman traits: the capacity to extend lifespans and even achieve immortality, the intervention to create new life forms, to become gifted designers of our own Eden, the means to end war, starvation, and disease. There will be a price to pay for this power, however. Homo Deus is easily one of the most interesting, human narratives, in a way that makes you think of new ideas. It has triggered me to doubt our whole human endeavour. There is a wealth of detail, in this tome, and it is probably a narrative, which we need to be reread. | 1 |
| A must read | darren | 20 March 2017 | 1 | Format: Kindle Edition | 5 | Following on from Sapiens this easy to read sequel will expand your mind. You may have developed a different outlook on life once you have read this. | 1 |
Looks like a good start to me! Next, I’ll analyse and compare word sentiments between the two books. To achieve this, I write a function that breaks down review sentences into separate words and removes common English stop words, such as you, at, above, etc.
### sentiment analysis ####
# Split a column with the reviews into separate words
words_function <- function(df){
df_words <- df %>%
select(date, comments, stars) %>%
unnest_tokens(word, comments)
data("stop_words")
df_words <- df_words %>%
anti_join(stop_words)
df_words
}
sapiens_words <- words_function(sapiens_reviews)
homo_deus_words <- words_function(homo_deus_reviews)
Now, there are several approaches to quantifying the amount of different sentiments in text (and thus using different relevant R lexicons) : you can associate a word with a given emotion, like joy, sadness, fear etc. (NRC lexicon), express whether a word is positive or negative (bing lexicon) or give it a numeric score between -5 and 5, where values under 0 indicate a negative sentiment and above 0 - the positive. Words scoring close to or equal zero are neutral (afinn lexicon).
get_sentiments("bing") %>% head
## # A tibble: 6 × 2
## word sentiment
## <chr> <chr>
## 1 2-faced negative
## 2 2-faces negative
## 3 a+ positive
## 4 abnormal negative
## 5 abolish negative
## 6 abominable negative
get_sentiments("nrc") %>% head
## # A tibble: 6 × 2
## word sentiment
## <chr> <chr>
## 1 abacus trust
## 2 abandon fear
## 3 abandon negative
## 4 abandon sadness
## 5 abandoned anger
## 6 abandoned fear
get_sentiments("afinn") %>% head
## # A tibble: 6 × 2
## word score
## <chr> <int>
## 1 abandon -2
## 2 abandoned -2
## 3 abandons -2
## 4 abducted -2
## 5 abduction -2
## 6 abductions -2
I decided to use bing and afinn lexicons for my analysis, so all I need to do now is to use left_join() to add both of them to my data:
sapiens_words <- sapiens_words %>%
left_join(get_sentiments("bing"), by = "word") %>%
left_join(get_sentiments("afinn"), by = "word") %>%
mutate(book = "Sapiens") %>% unique()
homo_deus_words <- homo_deus_words %>%
left_join(get_sentiments("bing"), by = "word") %>%
left_join(get_sentiments("afinn"), by = "word") %>%
mutate(book = "Homo Deus") %>% unique()
all_words <- bind_rows(sapiens_words, homo_deus_words)
all_words %>% arrange(sentiment) %>% head() %>% kable()
| date | stars | word | sentiment | score | book |
|---|---|---|---|---|---|
| 12 January 2017 | 5 | unbelievably | negative | NA | Sapiens |
| 23 December 2016 | 4 | unusual | negative | NA | Sapiens |
| 11 March 2017 | 5 | mess | negative | -2 | Sapiens |
| 6 March 2017 | 5 | unnerving | negative | NA | Sapiens |
| 7 October 2014 | 4 | qualms | negative | NA | Sapiens |
| 7 October 2014 | 4 | slur | negative | NA | Sapiens |
Now we’re ready to explore! For the start, comparing star ratings should give me a flavour of how positive the reviews were. Based on the distribution of stars, it looks like Homo Deus has more positive reviews than Sapiens (conversely to my predictions!):
all_words %>%
group_by(book, stars) %>%
summarize(n_stars = n()) %>%
group_by(book) %>%
mutate(n_reviews = sum(n_stars),
percent = paste0(round(n_stars*100/n_reviews, 0), "%")) %>%
select(-c(n_stars, n_reviews)) %>%
spread(stars, percent)
## Source: local data frame [2 x 6]
## Groups: book [2]
##
## book `1` `2` `3` `4` `5`
## * <chr> <chr> <chr> <chr> <chr> <chr>
## 1 Homo Deus 1% 11% 6% 30% 52%
## 2 Sapiens 7% 14% 20% 22% 37%
Is the same trend shown in the afinn sentiment score?
all_words %>%
ggplot(aes(x= book, y = score, color = book, fill = book)) +
geom_boxplot(outlier.shape=NA, alpha = 0.3) + #avoid plotting outliers twice
scale_color_manual(values=c("#333333", "#CC0000")) +
scale_fill_manual(values=c("#333333", "#CC0000"))
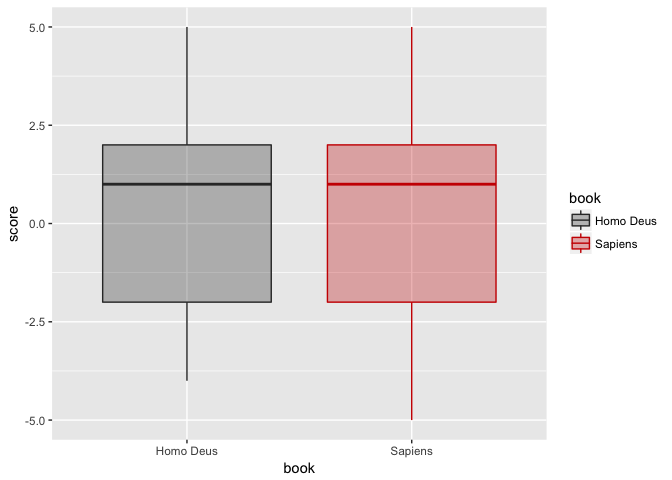
Not at all! Distribution of afinn sentiment score for both books looks very similar. Does it mean that the star number reflects different level of positivity in different book? Let’s have a look:
### average sentiment score per star
all_words %>%
ggplot(aes(as.factor(stars), score)) +
geom_boxplot(aes(fill = book), alpha = 0.3) +
xlab("Number of stars")+
scale_color_manual(values=c("#333333", "#CC0000")) +
scale_fill_manual(values=c("#333333", "#CC0000"))
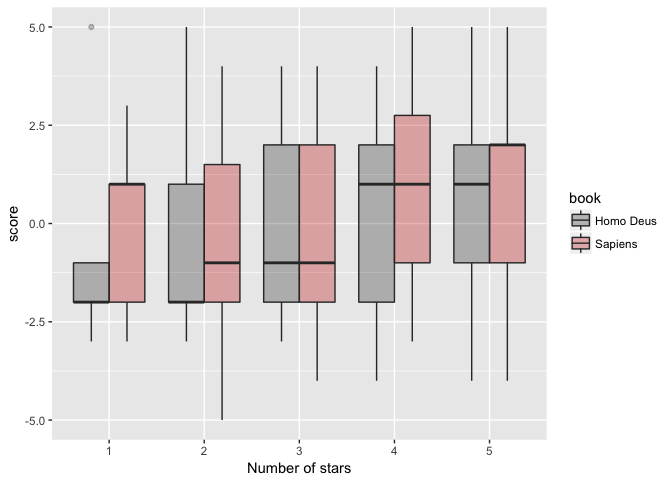
Not quite. Although the within-star_number difference in sentiment are not drastically different between the two books, indeed Sapiens tends to have its medians shifted upwards compared to Homo Deus.
Will bing lexicon show similar patterns?
## ratio of positive / negative words per review
all_words %>%
filter(!is.na(sentiment)) %>%
group_by(book, sentiment) %>%
summarise(n = n() ) %>%
group_by(book) %>%
mutate(sum = sum(n),
percent = paste0(round(n*100/sum, 0), "%")) %>%
select(-c(n, sum)) %>%
spread(sentiment, percent)
## Source: local data frame [2 x 3]
## Groups: book [2]
##
## book negative positive
## * <chr> <chr> <chr>
## 1 Homo Deus 47% 53%
## 2 Sapiens 42% 58%
And again, the sentiments seem to be very similar for both books, this time reflected in the proportion of positive words. How is this possible, given that Sapiens received relatively fewer 4- and 5-star reviews than Homo Deus?
### ratio of positive / negative words per star per review
all_words %>%
filter(!is.na(sentiment)) %>%
group_by(book, stars, sentiment) %>%
summarise(n = n()) %>%
group_by(book, stars) %>%
mutate(sum = sum(n),
percent = paste0(round(n*100/sum, 0), "%"),
percent2 = round(n/sum, 3)) %>%
select(-c(n, sum, percent)) %>%
spread(sentiment, percent2) %>%
ggplot(aes(x = stars, y = positive, fill = book)) +
geom_bar(stat = "identity", position = position_dodge(), colour="black", alpha = 0.6) +
scale_y_continuous(labels = scales::percent) +
scale_color_manual(values=c("#333333", "#CC0000")) +
scale_fill_manual(values=c("#333333", "#CC0000")) +
coord_flip()
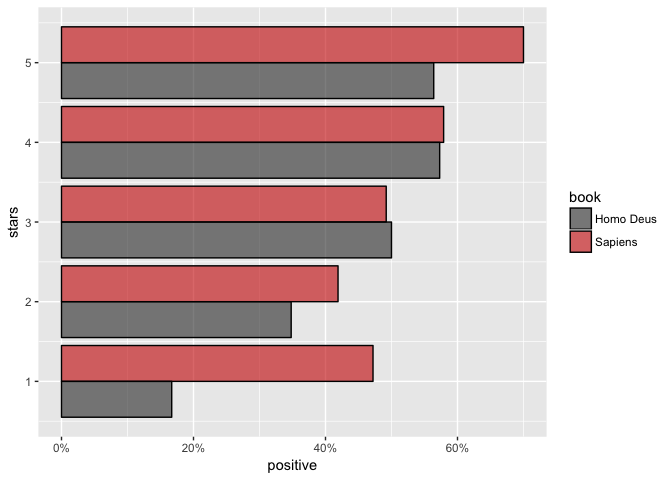
Because Sapiens reviews contain overall higher proportion of positive words across pretty much all the reviews except 3-star ones, that’s why!
It’s all good so far, but comparing sentiments based on separate words can sometimes give misleading results, as such analysis does not take into account negations (e.g. I am *not passionate about singing.) or amplifiers (I really like this song*), etc. So, I used sentimentR package to compare sentiments of whole sentences.
#### scoring sentences with sentimentr ####
# install.packages("devtools")
devtools::install_github("trinker/lexicon")
devtools::install_github("trinker/sentimentr")
## combining data.frames
sapiens_reviews <- sapiens_reviews %>%
mutate(book = "Sapiens")
homo_deus_reviews <- homo_deus_reviews %>%
mutate(book = "Homo Deus")
all_reviews <-bind_rows(sapiens_reviews, homo_deus_reviews)
out2 <- with(all_reviews, sentiment_by(comments, book))
sentimentR is a great little gem for text mining: it’s very fast, performs tokenization within the library (no need to call tidytext::unnest_tokens() separately), gives an option to group results by other variables and produces pretty graphs :)
# sentiment scores by sentence
head(out2)
## book word_count sd ave_sentiment
## 1: Homo Deus 12617 0.3851959 0.1736843
## 2: Sapiens 14024 0.4570880 0.2002676
# plotting sentiment scores by sentence
plot(out2)
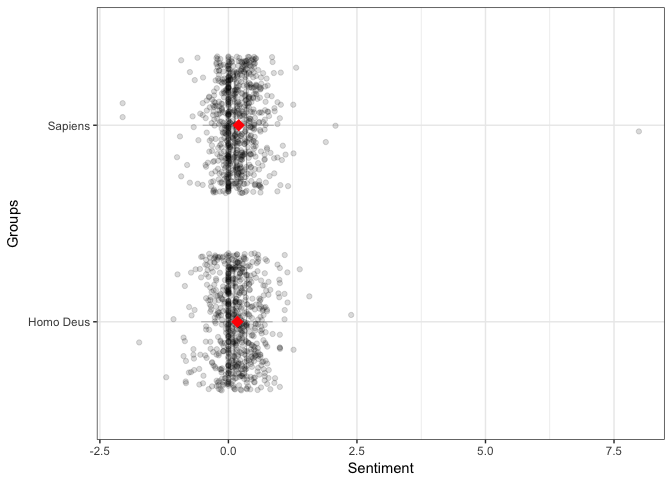
Again, like with previous approaches, sentence - level sentiment looks very similar for both books, perhaps with Sapiens being marginally more positive. However, the really interesting stuff starts when we look at those sentiments grouped by the book AND the number of stars:
out3 <- with(all_reviews, sentiment_by(comments, list(book, stars)))
out3
## book stars word_count sd ave_sentiment
## 1: Homo Deus 1 83 0.2326113 -0.10015893
## 2: Homo Deus 2 2063 0.3924527 -0.10080533
## 3: Homo Deus 3 617 0.2916933 0.08885353
## 4: Homo Deus 4 3529 0.3037805 0.22660451
## 5: Homo Deus 5 6325 0.3993962 0.22717875
## 6: Sapiens 1 1355 0.2874542 0.02951020
## 7: Sapiens 2 1626 0.3535837 0.10415064
## 8: Sapiens 3 3164 0.3823897 0.06622241
## 9: Sapiens 4 2648 0.3373602 0.22689740
## 10: Sapiens 5 5231 0.5565202 0.31460320
plot(out3)
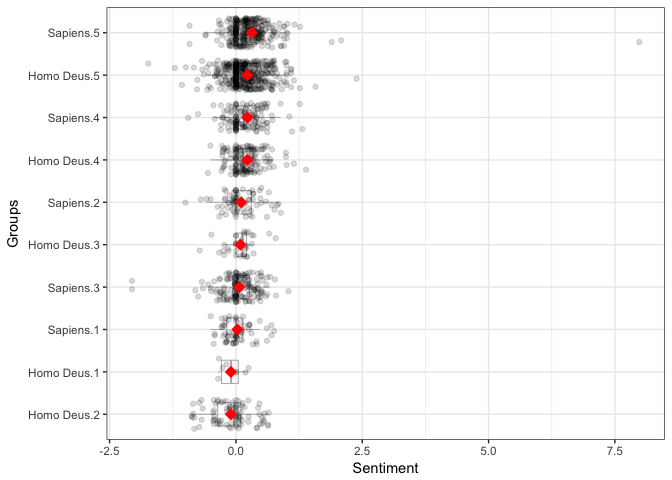
As you can see, number of stars given by the reviewer doesn’t always exactly reflect its sentiment! Here, I mean examples where fewer - stars reviews show higher sentiment than those reviews with more stars. But it’s fair to say that this seem to be off the general trend where number of stars positively correlates with the sentence-levels sentiment score. And again, Sapiens reviews with 5 stars are much more positive than respective Homo Deus reviews. At the same time, the more critical reviews with 1 and 2 stars are more negative for Homo Deus than they are for Sapiens. Together, this explains why at the book level the sentiment score is very similar between the two books, despite Homo Deus’ receiving much more 5-star reviews overall.
Now, it becomes clear how naive my predictions were about comparing sentiment scores betweeen the two books! Obviously, when comparing clearly bad and good books you will find striking differences in reviews’ sentiments, but when comparing two highly regarded books written by the same author it’s clear that there will be nuances and complexities to it.
TAKE HOME POINTS
-
Homo Deus received more positive (4 & 5-star) reviews than Sapiens, however
-
both books had very similar sentiments level based on both, word- and sentence-level scores.
-
It was mainly due to Sapiens receiving higher sentiment scores for both, most positive and most negative reviews.
-
overall, different approaches to sentiment analysis showed consistent results, which is reassuring :-)
funny fact from writing this blog post: throughout the process I’ve been writing Deus Ex or deus_ex instead of Homo Deus and homo_deus respectively, and I only realised it after my partner read the final version of this post… oops!
TECHNICAL RANT
This post took WAAAY longer that it should, mainly because first I tried using RSentiment package for the sentence-level analysis. Unfortunately, this package proved to be very buggy: returns named vectors when evaluating single sentences with score_sentence(), does not correctly evaluate sentences with special characters and, let me say it, it is excruciatingly slow. I guess it is the lesson to choose your tools wisely.